1. 서론
1.1. 연구 노트 개요
본 문서는 후술될 연구의 진행 과정을 기록하고 공유하는데 목적을 둔다. 날짜별로 산출물을 정리하고 게시하여, 연구의 투명성과 재현성을 높이고자 한다.
1.2. 연구 주제 및 목표
본 연구는, Ted Underwood(2018)의 "Why Literary Time is Measured in Minutes"[1]를 기반으로 소설 속 시간 흐름을 측정하는 간편한 파이썬 라이브러리를 개발하고, 그것을 근현대 한국 소설에 적용하는 것을 목표로 한다.
구체적인 내용은 연구계획서를 참고하길 바란다.
2. 연구 노트
2.1. 2025-09-05
- 최초의 연구계획서가 작성된 날이다.
- 처음에는 Underwood(2018)의 연구를 단순히 재현하는 것을 목표로 삼았다. 이때 이 연구의 가치는 인문 연구자들의 연구 편의성과 접근성을 위해, 사용하기 편한 파이썬 라이브러리를 산출하고 배포하는데 있다.
- 연구계획서
2.2. 2025-09-05 - 2025-09-15
- 본격적인 연구의 재현 작업이 시작되었다.
- 상술된 "Why Literary Time is Measured in Minutes"를 간략하게 가공한 버전의 코드[3]가 Underwood에 의해 GitHub에 공개되어 있다. 이를 바탕으로 fic-time이라 명명한 파이썬 라이브러리를 개발 완료하였다.
- fic-time은 현재 Test PyPi 에 게시되어 있으며, 다음 코드로 설치해 볼 수 있다.
pip install -i https://test.pypi.org/simple/ fic-time
GitHub Link [4] - 9월 15일에 진행한 연구진척발표자료(250915)를 참고해도 좋다.
- 추가로 협성대학교 문예창작과 소속의 김병호(시 전공) 교수님께 연구계획을 설명드리고 조언을 구하였다. 주로 구체적인 실용성에 대한 의문을 표하셨다. (2025-09-10)
2.3. 2025-09-16 - 2025-09-22
- 연구의 방향성이 약간 변경되었다. 기존에는 Underwood의 연구 성과를 파이썬 라이브러리로 만들어 배포하는 것이었는데, 새로운 목표는 국문 현대소설에 Underwood의 연구를 적용하는 것이 되었다.
- AKS 소속의 김병준 교수와의 면담 끝에 목표가 변경되었다. 국문 전환을 제안하셨다.
- 면담 내용은 연구진척발표자료(250921)를 참고하길 바란다.
- 지난 9월 10일에 제기받은 구체적인 실용성 측면 또한, 김병준 교수님에 의해 확보되었다. 국문 전환과 연구 접근성을 위한 라이브러리 제작 모두 디지털인문학에서 유의미하다는 조언을 들었다.
- 본 연구진척 발표 과정에서, 협성대학교 소프트웨어공학과 소속의 박혜승 교수님께 연구과제신청을 해보는 것이 어떠냐는 제안을 받았다. 이로서 박혜승 교수님이 교신저자로 참여하여, 학교의 지원을 받을 수 있게 되었다.
2.4. 2025-09-23 - 2025-09-29
- 구체적인 연구과제신청서가 완성되었다. 아낌없이 조언을 해 주신 김병준 교수님과 김병호 교수님과 박혜승 교수님께 감사를 전한다.
- 이 연구과제신청서는, 서론에 명시된 연구계획서이다. 이 문서를 바탕으로 박혜승 교수님께서 학교에 연구과제신청을 진행하셨다.
2.5. 2025-09-30 - 2025-11-01
- 중간고사와 기타 여러 일로 인하여 긴 시간 연구 진척이 미비했다.
- 이 기간동안은 주로 데이터셋을 어떻게 구성해야 하는지를 고민하였다.
- '공유마당'이라 부르는 웹페이지에서 다양한 텍스트를 제공하는 것을 확인하였다. 좌측의 링크[5]는 저작권이 만료된 국문 근대소설 목록이다.
2.6. 2025-11-02
- 라벨링 대상이 될 소설 목록을 정하는 것에 난항을 겪던 중, 협성대학교 소속의 구광본(소설 전공) 교수님에게 조언을 구하였다.
- 조언 내용은 매우 유익했다.
- 예술 사조에 따른 시간 흐름의 경향성이 존재할테니, 그것이 치우치지 않게끔 해야 한다.
- 예를 들면, 극단적인 심리소설은 소설 전체의 시간 흐름이 한 순간에 불과할 수 있다. (극단적인 심리소설을 배제하는 것을 고려하라.)
- 이야기되는 시간과 이야기하는 시간에 대한 고찰이 필요하다. (이 부분은 Underwood도 동일하게 접근함. 3개의 시간 종류를 라벨링 함.)
- 저작권이 만료된 일제강점기 근처의 근대문학 말고, 사후 시간흐름에 의한 저작권 만료 현대소설도 찾아보라.
- 다음 목표는 한국 문학의 지형을 논하는 학위논문을 찾아서, 예술 사조별 작가 목록을 확보하는 것이다.
- 조언과 별개로, 문장 단위로 잘 가공된 tsv 파일에 손쉽게 라벨링을 수행할 수 있는 도구를 개발하였다. 구체적인 기능 목록과 깃허브 링크는 다음과 같다.
(Claude Sonnet 4.5를 기반으로 만들었다. 정말 놀라운 성능이다... 감탄을 금치 못하겠다.)- 기능 목록:
- csv, tsv, json에 대한 파일 입출력 가능. (형식 변환도 가능.)
- 상술한 파일에 존재하는 속성(열)을 삭제, 추가, 순서 변경 기능 지원.
- 행 단위로 페이지를 넘기며, 각 행의 모든 내용 수정 가능.
- 매 행의 수정마다 수정 내용을 저장.
- GitHub Link
- 기능 목록:
- (예술 사조가 치우치지 않게)라벨링 대상 소설을 확정짓고 나면, 위의 도구를 통해 라벨링을 수행할 것이다.
2.7. 2025-11-03 - 2025-12-09
- 기말고사로 인해 일정이 상당히 지연되었다. 본 섹션을 작성하는 12월 9일 현재, 기말고사가 종료되었다.
- 라벨링 대상 작품 목록을 확정하였다. 다만, 기존의 목표는 개별 작품의 전문을 라벨링 하는 것이었지만, 현실적인 시간 문제로 인하여 각 작품의 일부 발췌문만 라벨링 하는 것으로 목표가 변경되었다. [1]의 연구에서 시행한 방법론을 그대로 적용하여, 개별 작품에 대하여 16 문장을 라벨링 하기로 결정하였다.
- 한편, 작품의 선정 방식도 변경하기로 하였다. 기존에는 한국 근대소설만을 대상으로 하였지만, [1]의 연구를 모방하여 작품의 시간적 범위와 장르 모두 확장하기로 하였다.
- [1]의 연구에서는 90편의 작품을 다음과 같은 종류로 선정하였다.
- Canonical works
- Popular fiction
- Control group (non fiction)
- 본 연구에서도 [1]과 유사한 기준을 적용하여, 다음의 80개 작품을 사용하기로 결정하였다. 이제 1906년부터 2019년까지의 작품을 선정하였으며, 소설이 아닌 작품도 일부 포함하였다.
- [1]의 연구에서는 90편의 작품을 다음과 같은 종류로 선정하였다.
- 25년 12월 09일 기준으로, 17편의 근대소설을 확보한 상태이다. (총 80편 중 17편 확보)
- 12월 말일까지 80편의 소설을 모두 확보하는 것이 목표이다.
- 저작권이 있는 작품 경우, 적절한 샘플링 방법을 마련하여 일부 발췌문만을 확보하는 것을 목표로 한다.
- 개별 작품에 대한 샘플링 문장이 확보되는 대로 fic-labeler에 업로드 하여 라벨링을 수행할 예정이다.
- 25년 12월 12일까지 웹서버에 fic-labeler를 배포하는 것이 목표이다.
- 구체적으로는, 웹으로 접속하여 미리 정제된 문장들에 대하여 라벨링을 수행할 수 있는 시스템을 구축하는 것이 목표이다.
- 개별 라벨러에게 키를 발급하고, 해당 키로 접속하여 라벨링을 수행하는 것이다.
- fic-labeler의 구조를 고려하여, 원문 텍스트를 적절히 샘플링하고 가공하는 스크립트의 작성 또한 목표에 포함된다.
- 현재 연구의 목표와 향후 계획을 다시 정리하면 다음과 같다.
- 목표 1: 선정된 80편의 작품에서 각각 16문장씩 샘플링 하여 시간 흐름을 라벨링 한다.
- 목표 2: fic-time 라이브러리의 성능을 검증한다. (한글 텍스트에 대하여 유효함을 통계적으로 검증.)
- 목표 3: fic-time 라이브러리를 활용하여, 한국 근현대소설의 문예사조별 시간 흐름의 특징을 분석한다.
- 이때 목표 2에서 연구가 종료될 수도 있다. 해당 경우 fic-time의 검증과 배포까지를 논문으로 정리하고, 목표 3은 별도의 후속 연구로 진행한다.
2.8. 2025-12-10 - 2025-12-20
- 본격적인 라벨링 작업이 시작되었다.
- fic-labeler를 12월 14일에 정상 배포하였고, 15일부터 라벨링 작업을 시작하였다.
- 15일에 짧은 회의를 통해, 논문과 깃허브에서 설명하는 라벨링 방법을 라벨러들에게 자세히 설명하였다.
- fic-labeler의 사용 방법 또한 상기 회의에서 함께 설명하였다.
- 현재 확보된 작품 숫자는 16개이며, 남은 64개 작품은 12월 31일까지 모두 fic-labeler에 업로드 할 예정이다.
- 실제 도서를 읽고 텍스트를 컴퓨터로 타이핑 할 에정이다.
- 12월 19일에, 페이지 범위 내에서 무작위 페이지를 선택해주고, 해당 페이지들의 문장을 입력하면 자동으로 json으로 압축하는 웹 도구를 만들어 두었다.
- 12월 23일에 도서관에서 수집 가능한 모든 도서의 문장을 샘플링 하고, 도서관에서 갖고 있지 않은 작품은 직접 구매하여 샘플링을 수행할 예정이다.
2.9. 2025-12-21 - 2025-12-28
- 가볍게 생각했던 종이책의 라벨링 절차가 발목을 잡았다. 생각보다 까다로운 문제였다. 그러나 잘 해결했다. 적절한 샘플링용 시스템을 구축하여 웹서버에 올렸다. 적어도 내가 보기에는 통계적으로도 기술적으로도 문제가 없다. 구체적으로는 다음과 같다. (이것 때문에 항목 2.8. 의 목표를 전혀 달성하지 못했다. 1월 초에 최대한 많은 작품을 업로드 할 예정이다.)
- 책의 본문 시작 페이지와 끝 페이지 입력. 페이지 당 최대 행(일반적인 한 페이지의 행 개수) 개수 입력.
- 책의 페이지 수에 따라서, '페이지 당 글자 수'를 추정하기 위한 샘플링해야 할 페이지 무작위 추출. (단, 전체 구간을 샘플 개수의 절반 개수의 층으로 나누어, 각 층에서 동일한 횟수로 추출. (N^(1/2)개 샘플에 대하여, 샘플수의 절반의 층 생성. 추정치의 표준오차를 줄이기 위해 어느 정도의 균등함이 필요하다고 판단함.)
- 예: 300쪽 책 => 샘플은 18개 => 층은 9개 => 약 33쪽 크기의 개별 층 안에서, 2회씩 무작위 비복원 추출.
- 각 페이지의 사진을 촬영하여 업로드.
- CLOVA OCR로 사진 전송하여 원문 텍스트 받기.
- 서버에서 (PHP로)글자 수를 세고, p-value 계산. 유의수준 .005 이하로 페이지 당 글자 수가 추정되는지 확인.
- 책의 전체 범위를 0~1로 정하고, 실수 값으로 12개 포인트 산출. (처음 두 청크, 마지막 두 청크를 제외한 12개 청크의 상대 위치 산출.)
- [절차 6]에서 얻은 12개 포인트를, 앞서 샘플링으로 추출한 '페이지 당 글자수'와, 사람이 직접 입력한 '페이지 당 최대 행'을 사용하여, (페이지 번호, 시작 행)의 쌍으로 변환.
- 예시:
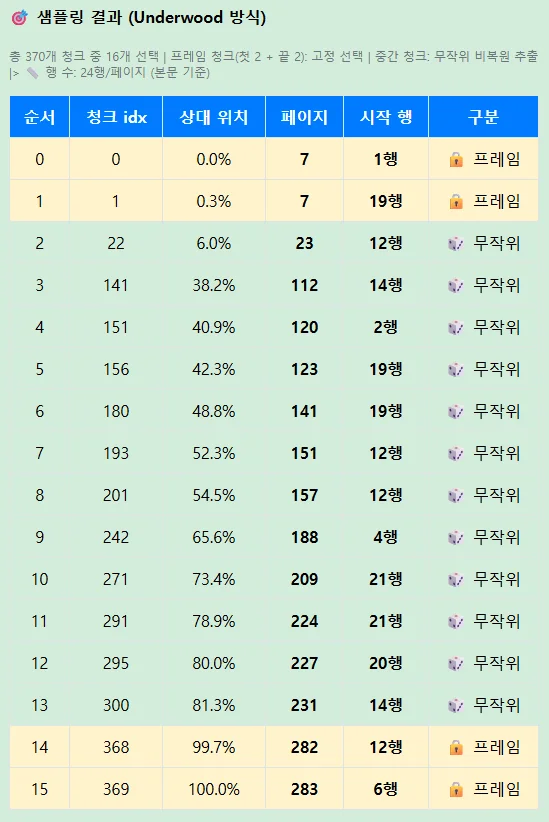
(클릭시 새창)
- 예시:
- 어떤가? 깔끔하지 않은가? 이것을 단독 연구로 포장할 수는 없을까 싶다. 간편한 책의 페이지당 글자 수 추정 도구? 다만 누가 이것을 사용하겠는가? 타겟이 모호하고 의의가 부족하다.
- 사실 Ollama로 minicpm-v:8b 를 가져와서 OCR을 수행하려고 시도했지만... 성능이 처참해서 포기했다. 내 서버의 메모리대역폭이 부족해서 더 큰 모델을 못 가져오는게 아쉽다 ㅜㅜ. 괜히 회원가입이 귀찮아서 약간 돌아가려다가 시간을 너무 많이 버렸다. 그건 그렇고, CLOVA의 인식 성능이 매우 놀랍다. 정확하다. 신규가입자한테 크레딧 10만원을 주는 것 또한 아주 시의적절하다.
- 그런데 논문 제목을 바꿔야한다. '현대'라는 단어를 빼야 한다.
2.10. 2025-12-28 - 2026-02-01
- 계속하여 소설을 샘플링하고, 시간을 기록하고 있다... (1월 31일에 41권을 달성하였다. 드디어 절반..!)
- 제3회 현대문학자대회에서 포스터 발표를 진행할 예정이다. 추후 작성할 석사논문의 초석으로서 기능하기를 바란다.
참고문헌
[1] T. Underwood, "Why literary time is measured in minutes," New Literary History, vol. 85, no. 2, pp. 351-365, 2018.
[2] T. Underwood, "Using GPT-4 to measure the passage of time in fiction," Mar. 19, 2023. [Online]. Available: https://tedunderwood.com/2023/03/19/using-gpt-4-to-measure-the-passage-of-time-in-fiction/
[3] T. Underwood, "fictional-time-with-GPT4," GitHub repository. [Online]. Available: https://github.com/tedunderwood/fictional-time-with-GPT4/tree/main
[4] 이시헌, "fic_time," GitHub repository, 2025. [Online]. Available: https://github.com/lamaBread/fic_time
[5] "공유마당 - 저작물 이용," 한국저작권위원회. [Online]. Available: https://gongu.copyright.or.kr/gongu/wrt/wrtCl/listWrtText.do?menuNo=200019&sortSe=date&licenseCd=97&searchWrd=소설&pageUnit=24&pageIndex=4. [Accessed: Nov. 1, 2025].